Note
Go to the end to download the full example code
Model Selection#
In Evaluating Performance, we saw how to check the performance of an
interpolator using cross-validation. We found that the default parameters for
verde.Spline are not good for predicting our sample air temperature
data. Now, let’s see how we can tune the Spline to improve the
cross-validation performance.
Once again, we’ll start by importing the required packages and loading our sample data.
import cartopy.crs as ccrs
import matplotlib.pyplot as plt
import numpy as np
import pyproj
import verde as vd
data = vd.datasets.fetch_texas_wind()
# Use Mercator projection because Spline is a Cartesian gridder
projection = pyproj.Proj(proj="merc", lat_ts=data.latitude.mean())
proj_coords = projection(data.longitude.values, data.latitude.values)
region = vd.get_region((data.longitude, data.latitude))
# The desired grid spacing in degrees
spacing = 15 / 60
Before we begin tuning, let’s reiterate what the results were with the default parameters.
spline_default = vd.Spline()
score_default = np.mean(
vd.cross_val_score(spline_default, proj_coords, data.air_temperature_c)
)
spline_default.fit(proj_coords, data.air_temperature_c)
print("R² with defaults:", score_default)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
R² with defaults: 0.7960368857078306
Tuning#
Spline has the damping regularization parameter which
smooths the solution and provides a least-squares fit to the data instead of
an exact fit at the observation points. This is often desirable to mitigate
data errors and provide better results when points are widely spaced. Would
changing the default values give us a better score?
We can answer this question by changing the values in our spline and
re-evaluating the model score repeatedly for different values of this
parameter. Let’s test the following values:
dampings = [None, 1e-4, 1e-3, 1e-2]
Now we can loop over each value and collect the scores for each parameter choice.
spline = vd.Spline()
scores = []
for damping in dampings:
spline.set_params(damping=damping)
score = np.mean(vd.cross_val_score(spline, proj_coords, data.air_temperature_c))
scores.append(score)
print(scores)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
[np.float64(0.7960368857078306), np.float64(0.8447749626698963), np.float64(0.8382287943019474), np.float64(0.8409658539039763)]
The largest score will yield the best parameter combination.
Best score: 0.8447749626698963
Score with defaults: 0.7960368857078306
Best damping: 0.0001
That is a nice improvement over our previous score!
This type of tuning is important and should always be performed when using a new gridder or a new dataset. However, the above implementation requires a lot of coding. Fortunately, Verde provides convenience classes that perform the cross-validation and tuning automatically when fitting a dataset.
Cross-validated gridders#
The verde.SplineCV class provides a cross-validated version of
verde.Spline. It has almost the same interface but does all of the
above automatically when fitting a dataset. The only difference is that you
must provide a list of damping values to try instead of only a single
value:
Calling fit will run a grid search over all parameter
values to find the one that maximizes the cross-validation score.
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/spline.py:245: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
spline = Spline(**params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/spline.py:245: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
spline = Spline(**params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/spline.py:245: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
spline = Spline(**params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/spline.py:245: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
spline = Spline(**params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/spline.py:261: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
self.spline_ = Spline(**parameter_sets[best])
The estimated best damping, as well as the cross-validation scores, are
stored in class attributes:
print("Highest score:", spline.scores_.max())
print("Best damping:", spline.damping_)
Highest score: 0.8447749626698963
Best damping: 0.0001
The cross-validated gridder can be used like any other gridder (including in
verde.Chain and verde.Vector):
<xarray.Dataset> Size: 18kB
Dimensions: (latitude: 43, longitude: 51)
Coordinates:
* latitude (latitude) float64 344B 25.91 26.16 26.41 ... 35.91 36.16 36.41
* longitude (longitude) float64 408B -106.4 -106.1 -105.9 ... -94.06 -93.8
Data variables:
temperature (latitude, longitude) float64 18kB 24.7 24.56 ... 7.542 7.639
Attributes:
metadata: Generated by SplineCV(dampings=[None, 0.0001, 0.001, 0.01], mi...
Like verde.cross_val_score, SplineCV can also run the
grid search in parallel using Dask by specifying the
delayed attribute:
spline = vd.SplineCV(dampings=dampings, delayed=True)
Unlike verde.cross_val_score, calling fit
does not result in dask.delayed.delayed objects. The full grid
search is executed and the optimal parameters are found immediately.
spline.fit(proj_coords, data.air_temperature_c)
print("Best damping:", spline.damping_)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/spline.py:245: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
spline = Spline(**params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/sklearn/base.py:129: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
new_object = klass(**new_object_params)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/model_selection.py:785: FutureWarning: The default scoring will change from R² to negative root mean squared error (RMSE) in Verde 2.0.0. This may change model selection results slightly.
score = estimator.score(*test_data)
/usr/share/miniconda/envs/test/lib/python3.12/site-packages/verde/spline.py:261: FutureWarning: The mindist parameter of verde.Spline is no longer required and will be removed in Verde 2.0.0. Use the default value to obtain the future behavior.
self.spline_ = Spline(**parameter_sets[best])
Best damping: 0.0001
The one caveat is the that the scores_ attribute will be a list of
dask.delayed.delayed objects instead because the scores are only
computed as intermediate values in the scheduled computations.
print("Delayed scores:", spline.scores_)
Delayed scores: [Delayed('mean-dc420882-10a2-4bd6-bcaa-b4713028dacc'), Delayed('mean-3328ed2c-3ca8-4a53-9642-eff4fe5c43d7'), Delayed('mean-b1a64c63-6ce0-484f-ab51-da8db9f00448'), Delayed('mean-eac40ad9-e653-4c75-a97a-3b086dd5e889')]
Calling dask.compute on the scores will calculate their values but
will unfortunately run the entire grid search again. So using
delayed=True is not recommended if you need the scores of each parameter
combination.
The importance of tuning#
To see the difference that tuning has on the results, we can make a grid with the best configuration and see how it compares to the default result.
grid_default = spline_default.grid(
region=region,
spacing=spacing,
projection=projection,
dims=["latitude", "longitude"],
data_names="temperature",
)
Let’s plot our grids side-by-side:
mask = vd.distance_mask(
(data.longitude, data.latitude),
maxdist=3 * spacing * 111e3,
coordinates=vd.grid_coordinates(region, spacing=spacing),
projection=projection,
)
grid = grid.where(mask)
grid_default = grid_default.where(mask)
plt.figure(figsize=(14, 8))
for i, title, grd in zip(range(2), ["Defaults", "Tuned"], [grid_default, grid]):
ax = plt.subplot(1, 2, i + 1, projection=ccrs.Mercator())
ax.set_title(title)
pc = grd.temperature.plot.pcolormesh(
ax=ax,
cmap="plasma",
transform=ccrs.PlateCarree(),
vmin=data.air_temperature_c.min(),
vmax=data.air_temperature_c.max(),
add_colorbar=False,
add_labels=False,
)
plt.colorbar(pc, orientation="horizontal", aspect=50, pad=0.05).set_label("C")
ax.plot(
data.longitude, data.latitude, ".k", markersize=1, transform=ccrs.PlateCarree()
)
vd.datasets.setup_texas_wind_map(ax)
plt.show()
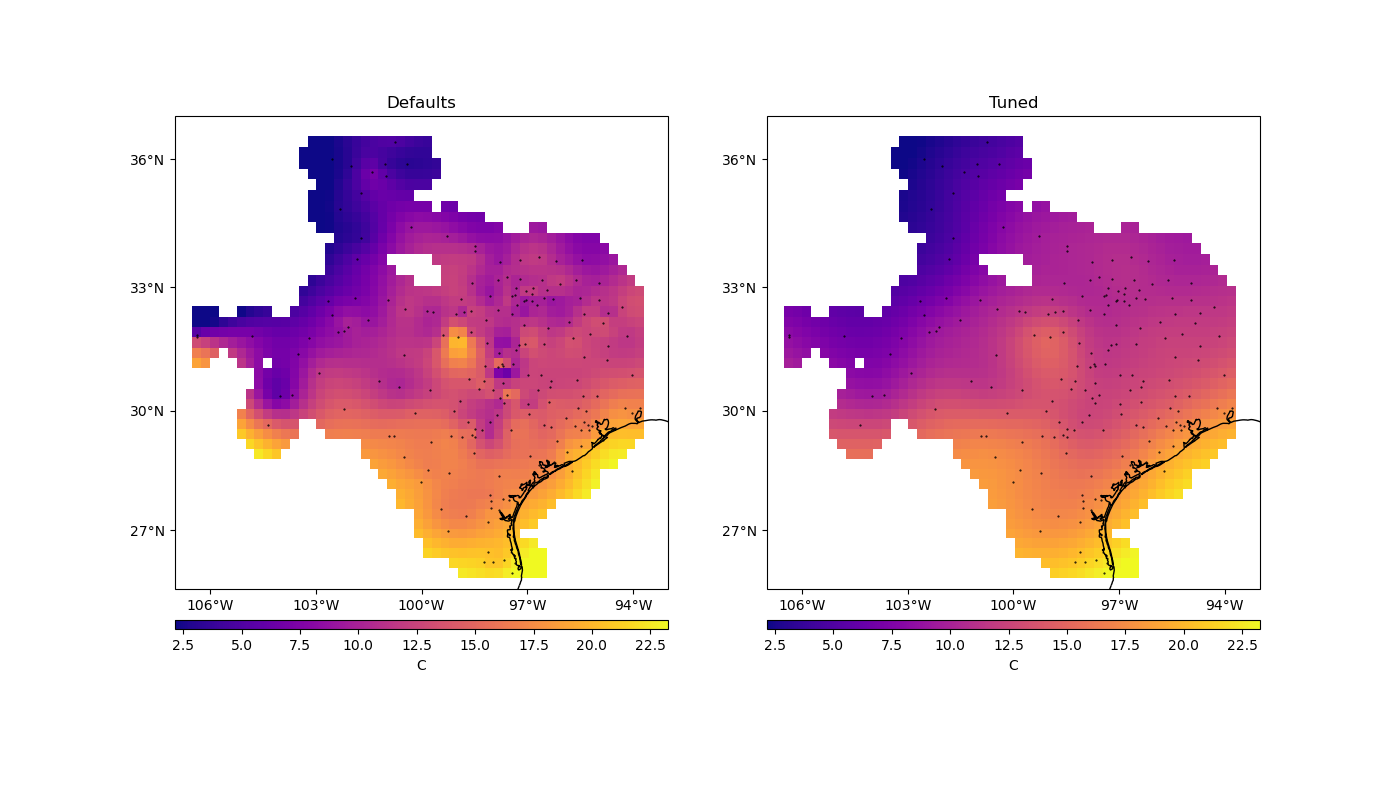
Notice that, for sparse data like these, smoother models tend to be better predictors. This is a sign that you should probably not trust many of the short wavelength features that we get from the defaults.
Total running time of the script: (0 minutes 0.510 seconds)