Note
Click here to download the full example code
Model Selection¶
In Evaluating Performance, we saw how to check the performance of an interpolator using
cross-validation. We found that the default parameters for verde.Spline are not
good for predicting our sample air temperature data. Now, let’s see how we can tune the
Spline to improve the cross-validation performance.
Once again, we’ll start by importing the required packages and loading our sample data.
import numpy as np
import matplotlib.pyplot as plt
import cartopy.crs as ccrs
import itertools
import pyproj
import verde as vd
data = vd.datasets.fetch_texas_wind()
# Use Mercator projection because Spline is a Cartesian gridder
projection = pyproj.Proj(proj="merc", lat_ts=data.latitude.mean())
proj_coords = projection(data.longitude.values, data.latitude.values)
region = vd.get_region((data.longitude, data.latitude))
# The desired grid spacing in degrees (converted to meters using 1 degree approx. 111km)
spacing = 15 / 60
Before we begin tuning, let’s reiterate what the results were with the default parameters.
spline_default = vd.Spline()
score_default = np.mean(
vd.cross_val_score(spline_default, proj_coords, data.air_temperature_c)
)
spline_default.fit(proj_coords, data.air_temperature_c)
print("R² with defaults:", score_default)
Out:
R² with defaults: 0.7960368854827115
Tuning¶
Spline has many parameters that can be set to modify the final result.
Mainly the damping regularization parameter and the mindist “fudge factor”
which smooths the solution. Would changing the default values give us a better score?
We can answer these questions by changing the values in our spline and
re-evaluating the model score repeatedly for different values of these parameters.
Let’s test the following combinations:
dampings = [None, 1e-5, 1e-4, 1e-3, 1e-2, 1e-1]
mindists = [5e3, 10e3, 25e3, 50e3, 75e3, 100e3]
# Use itertools to create a list with all combinations of parameters to test
parameter_sets = [
dict(damping=combo[0], mindist=combo[1])
for combo in itertools.product(dampings, mindists)
]
print("Number of combinations:", len(parameter_sets))
print("Combinations:", parameter_sets)
Out:
Number of combinations: 36
Combinations: [{'damping': None, 'mindist': 5000.0}, {'damping': None, 'mindist': 10000.0}, {'damping': None, 'mindist': 25000.0}, {'damping': None, 'mindist': 50000.0}, {'damping': None, 'mindist': 75000.0}, {'damping': None, 'mindist': 100000.0}, {'damping': 1e-05, 'mindist': 5000.0}, {'damping': 1e-05, 'mindist': 10000.0}, {'damping': 1e-05, 'mindist': 25000.0}, {'damping': 1e-05, 'mindist': 50000.0}, {'damping': 1e-05, 'mindist': 75000.0}, {'damping': 1e-05, 'mindist': 100000.0}, {'damping': 0.0001, 'mindist': 5000.0}, {'damping': 0.0001, 'mindist': 10000.0}, {'damping': 0.0001, 'mindist': 25000.0}, {'damping': 0.0001, 'mindist': 50000.0}, {'damping': 0.0001, 'mindist': 75000.0}, {'damping': 0.0001, 'mindist': 100000.0}, {'damping': 0.001, 'mindist': 5000.0}, {'damping': 0.001, 'mindist': 10000.0}, {'damping': 0.001, 'mindist': 25000.0}, {'damping': 0.001, 'mindist': 50000.0}, {'damping': 0.001, 'mindist': 75000.0}, {'damping': 0.001, 'mindist': 100000.0}, {'damping': 0.01, 'mindist': 5000.0}, {'damping': 0.01, 'mindist': 10000.0}, {'damping': 0.01, 'mindist': 25000.0}, {'damping': 0.01, 'mindist': 50000.0}, {'damping': 0.01, 'mindist': 75000.0}, {'damping': 0.01, 'mindist': 100000.0}, {'damping': 0.1, 'mindist': 5000.0}, {'damping': 0.1, 'mindist': 10000.0}, {'damping': 0.1, 'mindist': 25000.0}, {'damping': 0.1, 'mindist': 50000.0}, {'damping': 0.1, 'mindist': 75000.0}, {'damping': 0.1, 'mindist': 100000.0}]
Now we can loop over the combinations and collect the scores for each parameter set.
spline = vd.Spline()
scores = []
for params in parameter_sets:
spline.set_params(**params)
score = np.mean(vd.cross_val_score(spline, proj_coords, data.air_temperature_c))
scores.append(score)
print(scores)
Out:
[-6.672752075728899, 0.4845403172857198, 0.5491476726400855, 0.8383522700289948, 0.8373973052332208, 0.8371988991061018, 0.8384949172630931, 0.8276885599221611, 0.8335063005004766, 0.8401681583422075, 0.8379791028321062, 0.8373785156924592, 0.8351153077282858, 0.8316607509274716, 0.8477923403550243, 0.8492629930916282, 0.8444298795755929, 0.8418400888542905, 0.8371795091870735, 0.8412200336690431, 0.8371044537837982, 0.8529555082429294, 0.8530483081769951, 0.8521727667572396, 0.8401945161937985, 0.8330182923876798, 0.8207648785487809, 0.8441706458562251, 0.8472574508036811, 0.8491145591354643, 0.8196594276366461, 0.8125453034182787, 0.8020740590701518, 0.8347980600512589, 0.8412078872656968, 0.8427525325593759]
The largest score will yield the best parameter combination.
best = np.argmax(scores)
print("Best score:", scores[best])
print("Score with defaults:", score_default)
print("Best parameters:", parameter_sets[best])
Out:
Best score: 0.8530483081769951
Score with defaults: 0.7960368854827115
Best parameters: {'damping': 0.001, 'mindist': 75000.0}
That is a big improvement over our previous score!
This type of tuning is important and should always be performed when using a new gridder or a new dataset. However, the above implementation requires a lot of coding. Fortunately, Verde provides convenience classes that perform the cross-validation and tuning automatically when fitting a dataset.
Cross-validated gridders¶
The verde.SplineCV class provides a cross-validated version of
verde.Spline. It has almost the same interface but does all of the above
automatically when fitting a dataset. The only difference is that you must provide a
list of damping and mindist parameters to try instead of only a single value:
spline = vd.SplineCV(
dampings=[None, 1e-5, 1e-4, 1e-3, 1e-2, 1e-1],
mindists=[5e3, 10e3, 25e3, 50e3, 75e3, 100e3],
)
spline.fit(proj_coords, data.air_temperature_c)
The estimated best damping and mindist, as well as the cross-validation scores, are stored in class attributes:
print("Highest score:", spline.scores_.max())
print("Best damping:", spline.damping_)
print("Best mindist:", spline.mindist_)
Out:
Highest score: 0.8530483081769951
Best damping: 0.001
Best mindist: 75000.0
Finally, we can make a grid with the best configuration to see how it compares to the default result.
grid = spline.grid(
region=region,
spacing=spacing,
projection=projection,
dims=["latitude", "longitude"],
data_names=["temperature"],
)
print(grid)
Out:
<xarray.Dataset>
Dimensions: (latitude: 43, longitude: 51)
Coordinates:
* longitude (longitude) float64 -106.4 -106.1 -105.9 ... -94.06 -93.8
* latitude (latitude) float64 25.91 26.16 26.41 ... 35.91 36.16 36.41
Data variables:
temperature (latitude, longitude) float64 21.37 21.34 21.32 ... 7.858 8.07
Attributes:
metadata: Generated by SplineCV(client=None, cv=None, dampings=[None, 1e...
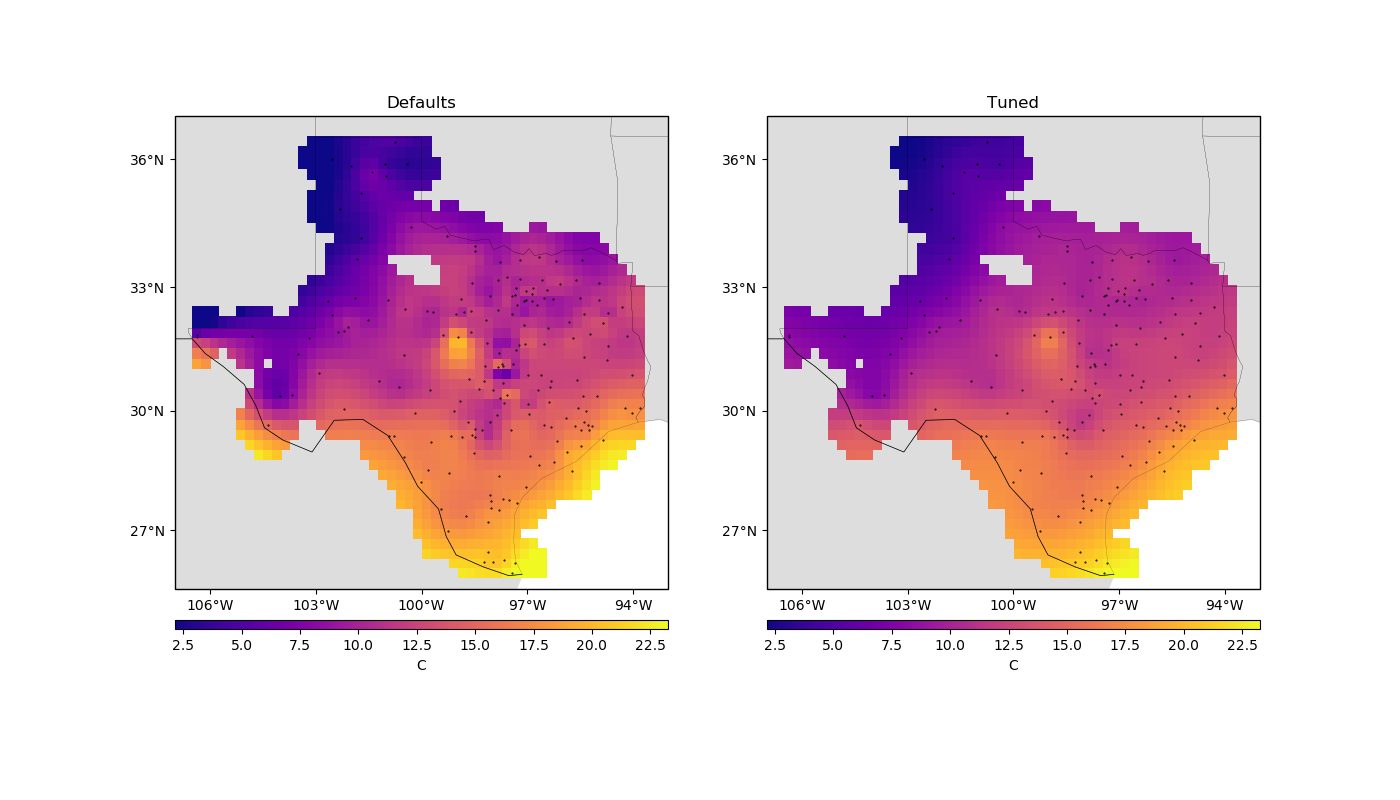
Let’s plot our grid side-by-side with one generated by the default spline:
grid_default = spline_default.grid(
region=region,
spacing=spacing,
projection=projection,
dims=["latitude", "longitude"],
data_names=["temperature"],
)
mask = vd.distance_mask(
(data.longitude, data.latitude),
maxdist=3 * spacing * 111e3,
coordinates=vd.grid_coordinates(region, spacing=spacing),
projection=projection,
)
grid = grid.where(mask)
grid_default = grid_default.where(mask)
plt.figure(figsize=(14, 8))
for i, title, grd in zip(range(2), ["Defaults", "Tuned"], [grid_default, grid]):
ax = plt.subplot(1, 2, i + 1, projection=ccrs.Mercator())
ax.set_title(title)
pc = grd.temperature.plot.pcolormesh(
ax=ax,
cmap="plasma",
transform=ccrs.PlateCarree(),
vmin=data.air_temperature_c.min(),
vmax=data.air_temperature_c.max(),
add_colorbar=False,
add_labels=False,
)
plt.colorbar(pc, orientation="horizontal", aspect=50, pad=0.05).set_label("C")
ax.plot(
data.longitude, data.latitude, ".k", markersize=1, transform=ccrs.PlateCarree()
)
vd.datasets.setup_texas_wind_map(ax)
plt.tight_layout()
plt.show()
Out:
/home/travis/build/fatiando/verde/tutorials/model_selection.py:169: UserWarning: Tight layout not applied. The left and right margins cannot be made large enough to accommodate all axes decorations.
plt.tight_layout()
Notice that, for sparse data like these, smoother models tend to be better predictors. This is a sign that you should probably not trust many of the short wavelength features that we get from the defaults.
Total running time of the script: ( 0 minutes 3.231 seconds)