verde.datasets.CheckerBoard¶
-
class
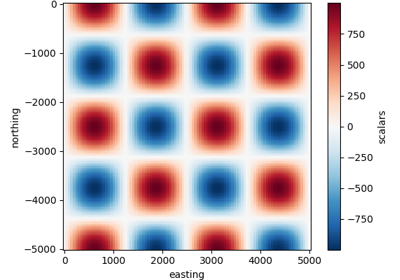
verde.datasets.CheckerBoard(amplitude=1000, region=(0, 5000, -5000, 0), w_east=None, w_north=None)[source]¶ Generate synthetic data in a checkerboard pattern.
The mathematical model is:
\[f(e, n) = a \sin\left(\frac{2\pi}{w_e} e\right) \cos\left(\frac{2\pi}{w_n} n\right)\]in which \(e\) is the easting coordinate, \(n\) is the northing coordinate, \(a\) is the amplitude, and \(w_e\) and \(w_n\) are the wavelengths in the east and north directions, respectively.
Parameters: - amplitude : float
The amplitude of the checkerboard undulations.
- region : tuple
The boundaries (
[W, E, S, N]) of the region used to generate the synthetic data.- w_east : float
The wavelength in the east direction. Defaults to half of the West-East size of the evaluating region.
- w_north : float
The wavelength in the north direction. Defaults to half of the South-North size of the evaluating region.
Examples
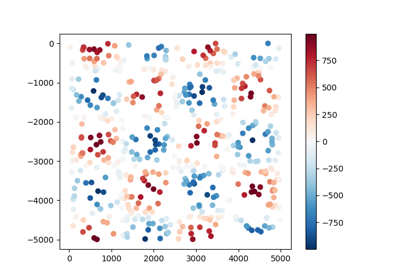
>>> synth = CheckerBoard() >>> # Default values for the wavelengths are selected automatically >>> print(synth.w_east_, synth.w_north_) 2500.0 2500.0 >>> # Checkerboard.grid produces an xarray.Dataset with data on a regular grid >>> grid = synth.grid(shape=(11, 6)) >>> type(grid) <class 'xarray.core.dataset.Dataset'> >>> # scatter and profile generate pandas.DataFrame objects >>> table = synth.scatter() >>> print(sorted(table.columns)) ['easting', 'northing', 'scalars'] >>> profile = synth.profile(point1=(0, 0), point2=(2500, -2500), size=100) >>> print(sorted(profile.columns)) ['distance', 'easting', 'northing', 'scalars']
Attributes: region_Used to fool the BaseGridder methods
w_east_Use half of the E-W extent
w_north_Use half of the N-S extent
Methods
filter(coordinates, data[, weights])Filter the data through the gridder and produce residuals. fit(coordinates, data[, weights])Fit the gridder to observed data. get_params([deep])Get parameters for this estimator. grid([region, shape, spacing, adjust, dims, …])Interpolate the data onto a regular grid. predict(coordinates)Evaluate the checkerboard function on a given set of points. profile(point1, point2, size[, dims, …])Interpolate data along a profile between two points. scatter([region, size, random_state, dims, …])Interpolate values onto a random scatter of points. score(coordinates, data[, weights])Score the gridder predictions against the given data. set_params(**params)Set the parameters of this estimator.
Examples using verde.datasets.CheckerBoard¶
-
CheckerBoard.filter(coordinates, data, weights=None)¶ Filter the data through the gridder and produce residuals.
Calls
fiton the data, evaluates the residuals (data - predicted data), and returns the coordinates, residuals, and weights.No very useful by itself but this interface makes gridders compatible with other processing operations and is used by
verde.Chainto join them together (for example, so you can fit a spline on the residuals of a trend).Parameters: - coordinates : tuple of arrays
Arrays with the coordinates of each data point. Should be in the following order: (easting, northing, vertical, …).
- data : array or tuple of arrays
The data values of each data point. If the data has more than one component, data must be a tuple of arrays (one for each component).
- weights : None or array or tuple of arrays
If not None, then the weights assigned to each data point. If more than one data component is provided, you must provide a weights array for each data component (if not None).
Returns: - coordinates, residuals, weights
The coordinates and weights are same as the input. Residuals are the input data minus the predicted data.
-
CheckerBoard.fit(coordinates, data, weights=None)¶ Fit the gridder to observed data. NOT IMPLEMENTED.
This is a dummy placeholder for an actual method.
Parameters: - coordinates : tuple of arrays
Arrays with the coordinates of each data point. Should be in the following order: (easting, northing, vertical, …).
- data : array or tuple of arrays
The data values of each data point. If the data has more than one component, data must be a tuple of arrays (one for each component).
- weights : None or array or tuple of arrays
If not None, then the weights assigned to each data point. If more than one data component is provided, you must provide a weights array for each data component (if not None).
Returns: - self
This instance of the gridder. Useful to chain operations.
-
CheckerBoard.get_params(deep=True)¶ Get parameters for this estimator.
Parameters: - deep : boolean, optional
If True, will return the parameters for this estimator and contained subobjects that are estimators.
Returns: - params : mapping of string to any
Parameter names mapped to their values.
-
CheckerBoard.grid(region=None, shape=None, spacing=None, adjust='spacing', dims=None, data_names=None, projection=None)¶ Interpolate the data onto a regular grid.
The grid can be specified by either the number of points in each dimension (the shape) or by the grid node spacing.
If the given region is not divisible by the desired spacing, either the region or the spacing will have to be adjusted. By default, the spacing will be rounded to the nearest multiple. Optionally, the East and North boundaries of the region can be adjusted to fit the exact spacing given. See
verde.grid_coordinatesfor more details.If the interpolator collected the input data region, then it will be used if
region=None. Otherwise, you must specify the grid region.Use the dims and data_names arguments to set custom names for the dimensions and the data field(s) in the output
xarray.Dataset. Default names are provided.Parameters: - region : list = [W, E, S, N]
The boundaries of a given region in Cartesian or geographic coordinates.
- shape : tuple = (n_north, n_east) or None
The number of points in the South-North and West-East directions, respectively. If None and spacing is not given, defaults to
(101, 101).- spacing : tuple = (s_north, s_east) or None
The grid spacing in the South-North and West-East directions, respectively.
- adjust : {‘spacing’, ‘region’}
Whether to adjust the spacing or the region if required. Ignored if shape is given instead of spacing. Defaults to adjusting the spacing.
- dims : list or None
The names of the northing and easting data dimensions, respectively, in the output grid. Defaults to
['northing', 'easting']for Cartesian grids and['latitude', 'longitude']for geographic grids. NOTE: This is an exception to the “easting” then “northing” pattern but is required for compatibility with xarray.- data_names : list of None
The name(s) of the data variables in the output grid. Defaults to
['scalars']for scalar data,['east_component', 'north_component']for 2D vector data, and['east_component', 'north_component', 'vertical_component']for 3D vector data.- projection : callable or None
If not None, then should be a callable object
projection(easting, northing) -> (proj_easting, proj_northing)that takes in easting and northing coordinate arrays and returns projected northing and easting coordinate arrays. This function will be used to project the generated grid coordinates before passing them intopredict. For example, you can use this to generate a geographic grid from a Cartesian gridder.
Returns: - grid : xarray.Dataset
The interpolated grid. Metadata about the interpolator is written to the
attrsattribute.
See also
verde.grid_coordinates- Generate the coordinate values for the grid.
-
CheckerBoard.predict(coordinates)[source]¶ Evaluate the checkerboard function on a given set of points.
Parameters: - coordinates : tuple of arrays
Arrays with the coordinates of each data point. Should be in the following order: (easting, northing, vertical, …). Only easting and northing will be used, all subsequent coordinates will be ignored.
Returns: - data : array
The evaluated checkerboard function.
-
CheckerBoard.profile(point1, point2, size, dims=None, data_names=None, projection=None)¶ Interpolate data along a profile between two points.
Generates the profile using a straight line if the interpolator assumes Cartesian data or a great circle if geographic data.
Use the dims and data_names arguments to set custom names for the dimensions and the data field(s) in the output
pandas.DataFrame. Default names are provided.Includes the calculated distance to point1 for each data point in the profile.
Parameters: - point1 : tuple
The easting and northing coordinates, respectively, of the first point.
- point2 : tuple
The easting and northing coordinates, respectively, of the second point.
- size : int
The number of points to generate.
- dims : list or None
The names of the northing and easting data dimensions, respectively, in the output dataframe. Defaults to
['northing', 'easting']for Cartesian grids and['latitude', 'longitude']for geographic grids. NOTE: This is an exception to the “easting” then “northing” pattern but is required for compatibility with xarray.- data_names : list of None
The name(s) of the data variables in the output dataframe. Defaults to
['scalars']for scalar data,['east_component', 'north_component']for 2D vector data, and['east_component', 'north_component', 'vertical_component']for 3D vector data.- projection : callable or None
If not None, then should be a callable object
projection(easting, northing) -> (proj_easting, proj_northing)that takes in easting and northing coordinate arrays and returns projected northing and easting coordinate arrays. This function will be used to project the generated profile coordinates before passing them intopredict. For example, you can use this to generate a geographic profile from a Cartesian gridder.
Returns: - table : pandas.DataFrame
The interpolated values along the profile.
-
CheckerBoard.scatter(region=None, size=300, random_state=0, dims=None, data_names=None, projection=None)¶ Interpolate values onto a random scatter of points.
If the interpolator collected the input data region, then it will be used if
region=None. Otherwise, you must specify the grid region.Use the dims and data_names arguments to set custom names for the dimensions and the data field(s) in the output
pandas.DataFrame. Default names are provided.Parameters: - region : list = [W, E, S, N]
The boundaries of a given region in Cartesian or geographic coordinates.
- size : int
The number of points to generate.
- random_state : numpy.random.RandomState or an int seed
A random number generator used to define the state of the random permutations. Use a fixed seed to make sure computations are reproducible. Use
Noneto choose a seed automatically (resulting in different numbers with each run).- dims : list or None
The names of the northing and easting data dimensions, respectively, in the output dataframe. Defaults to
['northing', 'easting']for Cartesian grids and['latitude', 'longitude']for geographic grids. NOTE: This is an exception to the “easting” then “northing” pattern but is required for compatibility with xarray.- data_names : list of None
The name(s) of the data variables in the output dataframe. Defaults to
['scalars']for scalar data,['east_component', 'north_component']for 2D vector data, and['east_component', 'north_component', 'vertical_component']for 3D vector data.- projection : callable or None
If not None, then should be a callable object
projection(easting, northing) -> (proj_easting, proj_northing)that takes in easting and northing coordinate arrays and returns projected northing and easting coordinate arrays. This function will be used to project the generated scatter coordinates before passing them intopredict. For example, you can use this to generate a geographic scatter from a Cartesian gridder.
Returns: - table : pandas.DataFrame
The interpolated values on a random set of points.
-
CheckerBoard.score(coordinates, data, weights=None)¶ Score the gridder predictions against the given data.
Calculates the R^2 coefficient of determination of between the predicted values and the given data values. A maximum score of 1 means a perfect fit. The score can be negative.
If the data has more than 1 component, the scores of each component will be averaged.
Parameters: - coordinates : tuple of arrays
Arrays with the coordinates of each data point. Should be in the following order: (easting, northing, vertical, …).
- data : array or tuple of arrays
The data values of each data point. If the data has more than one component, data must be a tuple of arrays (one for each component).
- weights : None or array or tuple of arrays
If not None, then the weights assigned to each data point. If more than one data component is provided, you must provide a weights array for each data component (if not None).
Returns: - score : float
The R^2 score
-
CheckerBoard.set_params(**params)¶ Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as pipelines). The latter have parameters of the form
<component>__<parameter>so that it’s possible to update each component of a nested object.Returns: - self