Note
Click here to download the full example code
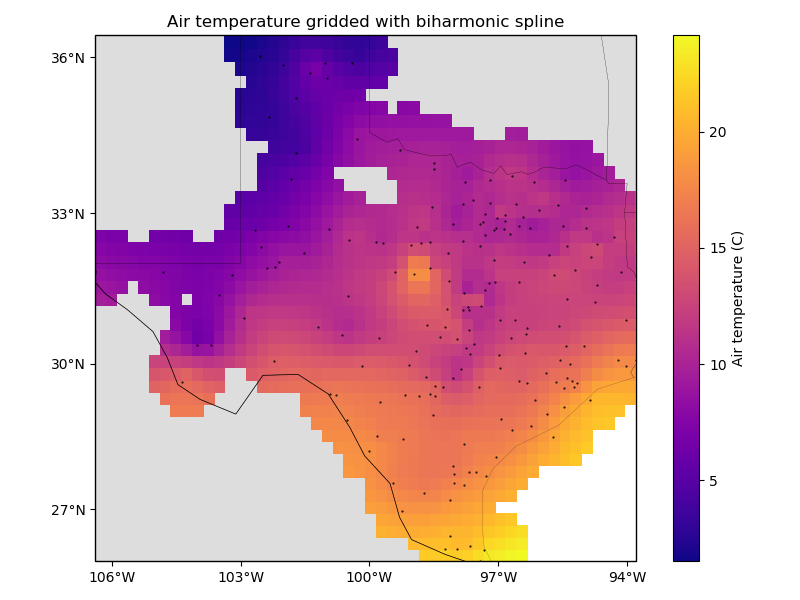
Gridding with splines¶
Biharmonic spline interpolation is based on estimating vertical forces acting on an
elastic sheet that yield deformations in the sheet equal to the observed data. The
results are similar to using verde.ScipyGridder with method='cubic' but
the interpolation is usually a bit slower. However, the advantage of using
verde.Spline is that we can assign weights to the data and do model selection.
Out:
Chain(steps=[('mean', BlockReduce(adjust='spacing', center_coordinates=False,
reduction=<function mean at 0x150b557c2d90>, region=None,
spacing=27750.0)), ('spline', Spline(damping=1e-10, engine='auto', force_coords=None, mindist=100000.0))])
Score: 0.856
<xarray.Dataset>
Dimensions: (latitude: 43, longitude: 51)
Coordinates:
* longitude (longitude) float64 -106.4 -106.1 -105.9 -105.6 -105.4 ...
* latitude (latitude) float64 25.91 26.16 26.41 26.66 26.91 27.16 ...
Data variables:
temperature (latitude, longitude) float64 nan nan nan nan nan nan nan ...
Attributes:
metadata: Generated by Chain(steps=[('mean', BlockReduce(adjust='spacing...
import matplotlib.pyplot as plt
import cartopy.crs as ccrs
import pyproj
import numpy as np
import verde as vd
# We'll test this on the air temperature data from Texas
data = vd.datasets.fetch_texas_wind()
coordinates = (data.longitude.values, data.latitude.values)
region = vd.get_region(coordinates)
# Use a Mercator projection for our Cartesian gridder
projection = pyproj.Proj(proj="merc", lat_ts=data.latitude.mean())
# The output grid spacing will 15 arc-minutes
spacing = 15 / 60
# Now we can chain a blocked mean and spline together. The Spline can be regularized
# by setting the damping coefficient (should be positive). It's also a good idea to set
# the minimum distance to the average data spacing to avoid singularities in the spline.
chain = vd.Chain(
[
("mean", vd.BlockReduce(np.mean, spacing=spacing * 111e3)),
("spline", vd.Spline(damping=1e-10, mindist=100e3)),
]
)
print(chain)
# We can evaluate model performance by splitting the data into a training and testing
# set. We'll use the training set to grid the data and the testing set to validate our
# spline model.
train, test = vd.train_test_split(
projection(*coordinates), data.air_temperature_c, random_state=0
)
# Fit the model on the training set
chain.fit(*train)
# And calculate an R^2 score coefficient on the testing set. The best possible score
# (perfect prediction) is 1. This can tell us how good our spline is at predicting data
# that was not in the input dataset.
score = chain.score(*test)
print("\nScore: {:.3f}".format(score))
# Now we can create a geographic grid of air temperature by providing a projection
# function to the grid method and mask points that are too far from the observations
grid_full = chain.grid(
region=region,
spacing=spacing,
projection=projection,
dims=["latitude", "longitude"],
data_names=["temperature"],
)
grid = vd.distance_mask(
coordinates, maxdist=3 * spacing * 111e3, grid=grid_full, projection=projection
)
print(grid)
# Plot the grid and the original data points
plt.figure(figsize=(8, 6))
ax = plt.axes(projection=ccrs.Mercator())
ax.set_title("Air temperature gridded with biharmonic spline")
ax.plot(*coordinates, ".k", markersize=1, transform=ccrs.PlateCarree())
tmp = ax.pcolormesh(
grid.longitude,
grid.latitude,
grid.temperature,
cmap="plasma",
transform=ccrs.PlateCarree(),
)
plt.colorbar(tmp).set_label("Air temperature (C)")
# Use an utility function to add tick labels and land and ocean features to the map.
vd.datasets.setup_texas_wind_map(ax, region=region)
plt.tight_layout()
plt.show()
Total running time of the script: ( 0 minutes 0.919 seconds)